Error handling
- Create a backup queue and set a backout threshold on the input queue. In many cases, a backup queue can help you know where to look for a failed message.
- Use Try, Catch block for the entire Flow.
- Use custom exception handling so that even the smallest bug can be analyzed and can be effectively removed.
- Logging mechanism :- Logging can be the most effective part as it can in turn become a performance hit. So effective logging mechanism should be present in the flow.
Backout Queue :-
While the MQ administrator sets the backout parameters, they are really used by well-behaved WebSphere MQ applications to remove potential “poisoned” messages from the queue, or messages that cannot be processed due to other issues. This is important for both shared queues and private queues, though the symptoms may differ. The parameters are:
BOQNAME(‘PRT.REQUEST.BOQ’)
Name of queue to which applications should write messages that have been backed out.
BOTHRESH (3)
Number of processing attempts for each message.
HARDENBO
Harden the backout counter to disk when syncpoint is done.
If a message on a private queue cannot be processed and a rollback is issued, that message goes back to the top of the queue. The next MQGET for that queue will pick the problem message up and try to process it again. If that attempt fails and the transaction is rolled back, the message once again goes to the top of the queue. WebSphere MQ maintains a backout count that can notify an application when it is looping on the same message. If the application ignores the backout counter, the first indication of a poison message is that a queue depth begins rising and the getting processes continues to run.
Limitations:-
- Use one backout queue per application, not per queue. One backout queue can be used for multiple request queues.
- Do not use the queue-manager-defined dead letter queue as the backout queue, because the contents of the backout queue are usually driven by the application. The dead letter queue should be the backout queue of last resort.
Exception Handling using Try Catch Block
A TryCatch node does not process a message in any way, it represents only a decision point in a message flow. When the TryCatch node receives a message, it propagates it to the Try terminal. The broker passes control to the sequence of nodes that are connected to that terminal (the try flow).
If an exception is thrown in the try flow, the broker returns control to the TryCatch node. The node writes the current contents of the exception list tree to the local error log, then writes the information for the current exception to the exception list tree, overwriting the information that is stored there.
The node propagates the message to the sequence of nodes that are connected to the Catch terminal (the catch flow). The content of the message tree that is propagated is identical to the content that was propagated to the Try terminal, which is the content of the tree when the TryCatch node first received it. The node enhances the message tree with the new exception information that it wrote to the exception list tree. Any modifications or additions that the nodes in try flow made to the message tree are not present in the message tree that is propagated to the catch flow.
Limitations:-
- Useful in small flows with less complexity and scenarios.
- Too many Try Catch node in large flows creates complexity.
- Too many Try Catch node in large flows leads to performance hit.
Custom Exception handling
Exception handling for big projects or Applications which consists of n number of flows can be customised.
The broker provides basic error handling for all message flows. If basic processing is not sufficient, and you want to take specific action in response to certain error conditions and situations, you can enhance your message flows to provide your own error handling.
For example, we might design a message flow that expects certain errors that you want to process in a particular way. Or perhaps our flow updates a database, and must roll back those updates if other processing does not complete successfully.
Because you can decide to handle different errors in different ways, there are no fixed procedures to describe. This section provides information about the principles of error handling, and the options that are available, and you must decide what combination of choices that you need in each situation based on the details that are provided in this section.
In these cases it is advisable to create a framework which can be made generic and can be reused throughout the flows.
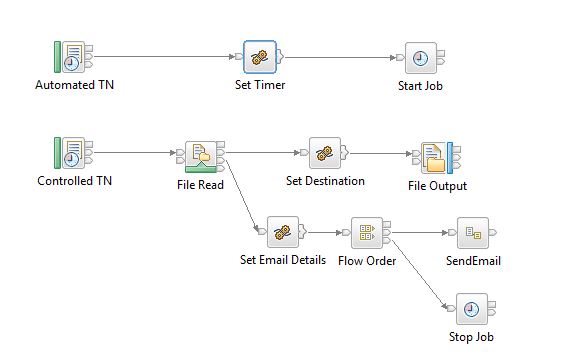
For example check the poison handler in the pic:-
Logging Mechanism:-
Logging can be the most effective way to analyze data for each scenario. So effective logging mechanism should be present in the flow not only for the happy scenario but also for analyzing the smallest errors or loopholes in the flows.
One of the ways is to integrate in the custom reusable components so that each input message can be logged irrespective of success or failure.
Also this can be evolved with the particular node names, timestamp and all other information as per requirement and severity.
Several ways of logging in IIB/WMB:-
- Database Logging
- Write to a file using IIB nodes
- Java Plugin
Limitations:-
- Database Logging can be in turn become a performance hit for the application. So decision to be taken depending upon the size and frequency of data. In this case database archiving can be implemented to overcome this sort of situation.
- Logging through Java log4net is an efficient way to maintain logging as it minimizes database hit but the only con it has is the files keep on piling up.